A Community Cache with Complete Information
1. 背景介绍
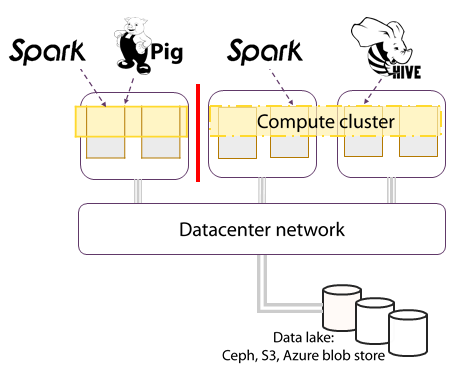
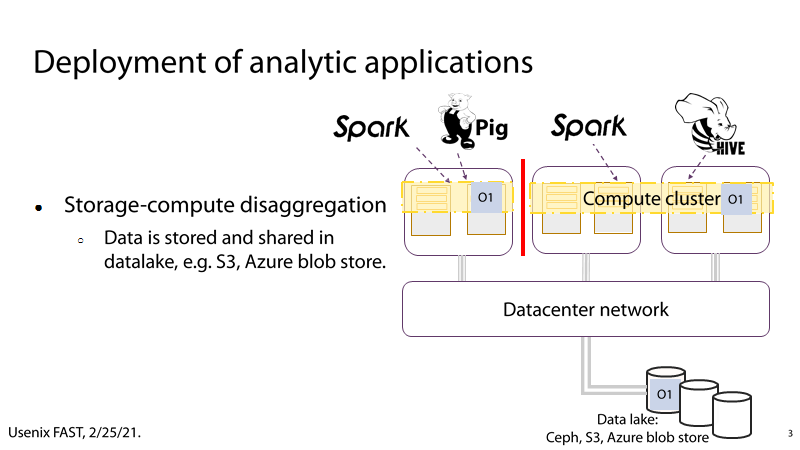
(1) P2:存算分离
P2:在现代的数据中心中,存储资源通常以资源池的形式呈现给计算集群,由计算集群共享存储资源,存储集群和计算集群使用互联网络相连。
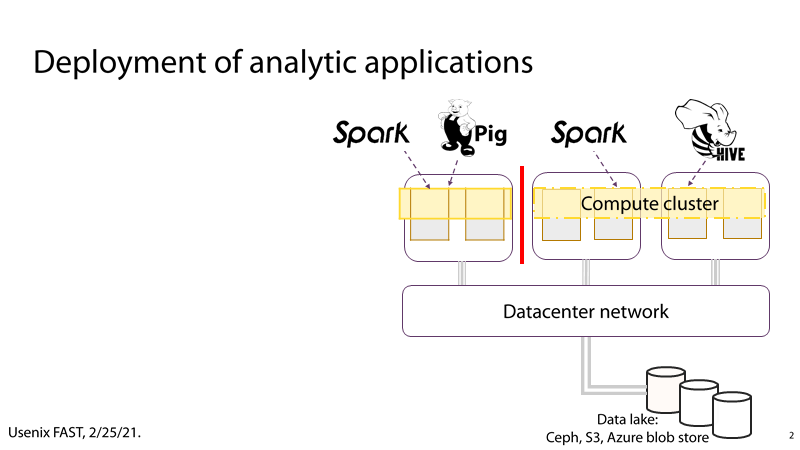
(2) P3:大数据分析应用的I/O瓶颈
P3:以大数据分析应用场景为例,部署在计算集群中的大数据分析框架通过互联网络从数据池中获取待分析的数据,这些数据通常是TB或者PB级,此时,频繁的I/O操作会占用大量的网络带宽,从而使I/O成为大数据分析过程的瓶颈。
2. 相关工作
(1) P4:Alluxio
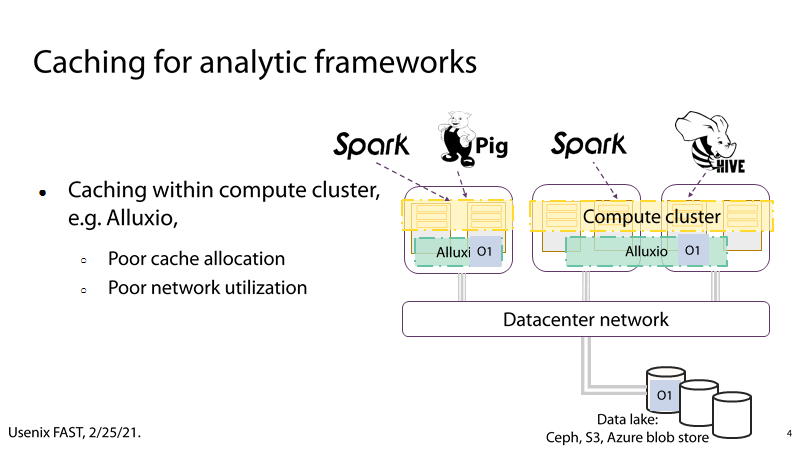
P4:Alluxio的通过在计算集群中增加Cache层来减轻网络负载,从而提高I/O性能。但是Alluxio的Cache分配和网络利用较为糟糕,例如,当两个分析框架使用相同的数据对象时,Alluxio会在计算集群中缓存两个O1对象,存在冗余和数据一致性的问题。
3.方案设计
(1) P5:Community cache
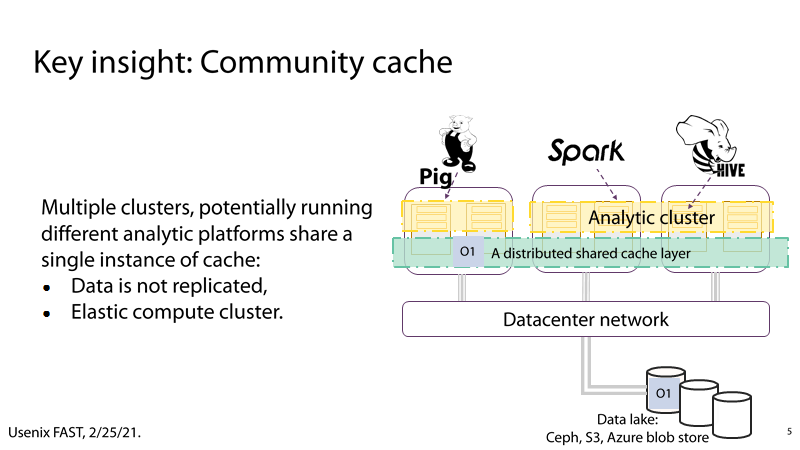
P5:通过采用Community Cache,可以消除Alluxio的缺点。即在运行不分析平台的多个集群中共享相同的数据缓存实例,这样做不仅可以解决数据冗余的问题,还能弹性拓展计算集群。
(2) P6:完整的信息
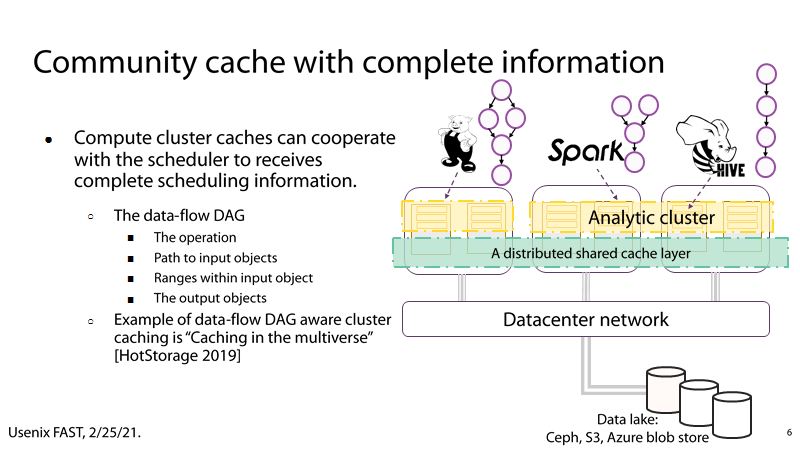
P6:计算集群缓存可以和集群的任务调度信息进行配合(任务的DAG数据流图),从而更好地利用缓存。
(3) P7:I/O数据流、网络和存储资源的使用情况
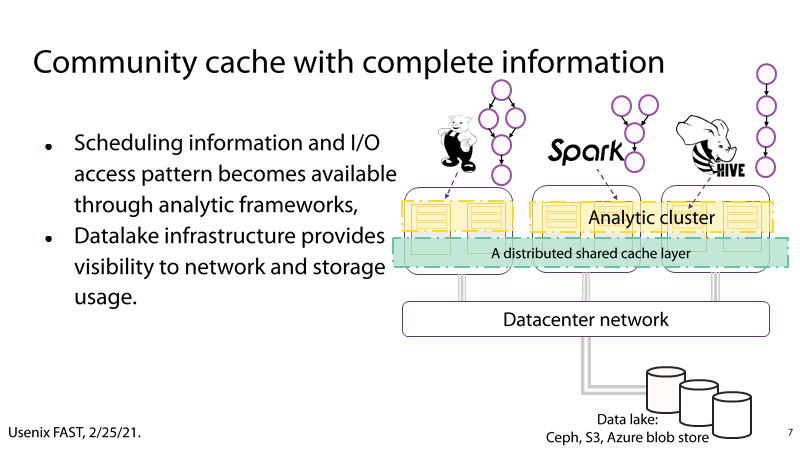
P7:一方面,可以通过在大数据分析框架获取任务调度信息和I/O数据流,另一方面,可以通过数据池获取实时的存储资源和网络的使用情况,
(4) P8:执行时间+缓存信息+带宽监测+I/O数据流 = 更好地缓存预测
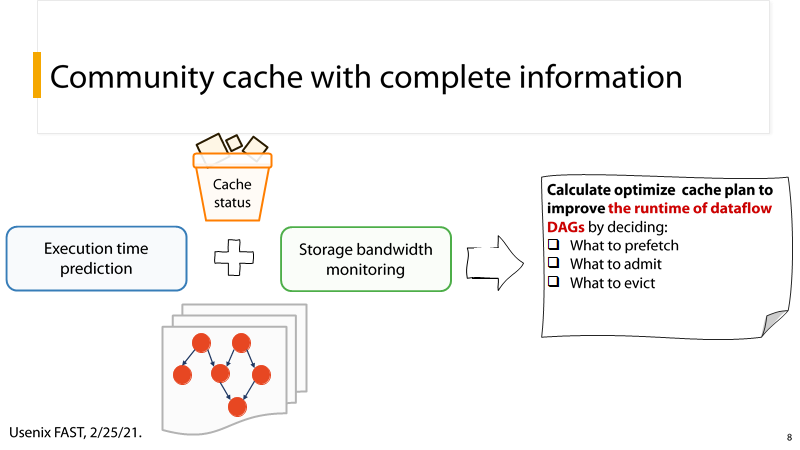
P8:利用执行时间+缓存信息+带宽监测+I/O数据流四方面的数据,可以实现更好地缓存预测。
4. 方案说明
(1) P9:CMR-最小化运行时间
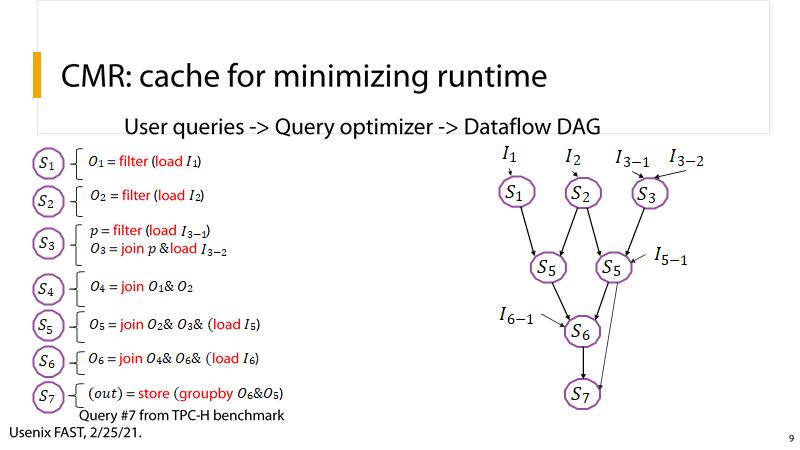
P9:下面以一个应用分析实例进行说明。用户编写的查询操作被分解为了数据流图,这一过程在应用实际执行之前就可以获得,此时,我们就得到了各个执行单元的I/O依赖关系.
(2) P10:共享缓存
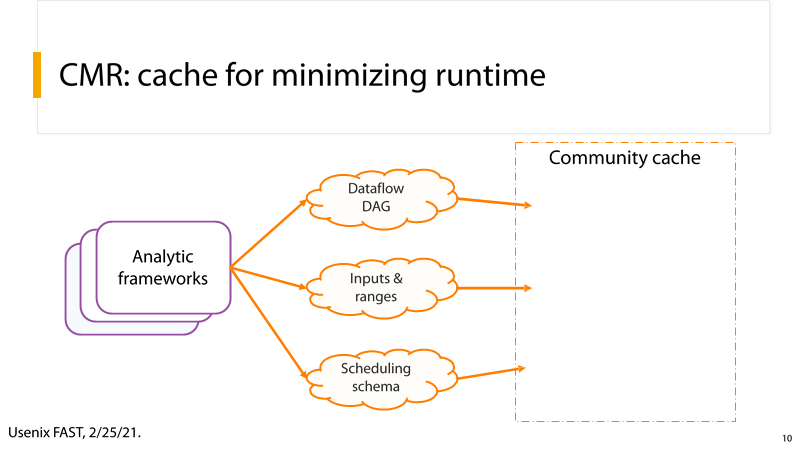
P10:Dataflow DAG、Inputs & ranges、Scheduling schema数据都可以从但数据分析框架中获取,Community Cache就可以利用这些信息更好地管理缓存,从而提升系统性能。
(3) P11:时空图
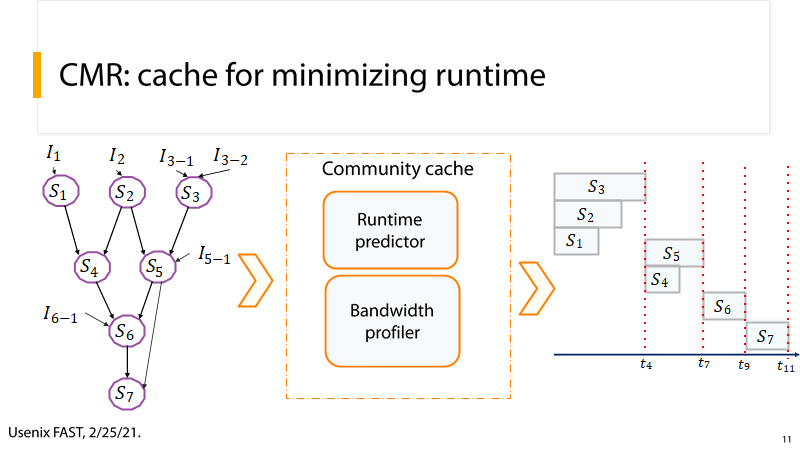
P11:通过各单元执行时间的预测信息,我们可以汇出时空图,如右图所示。通过这张图我们很容易看出关键路径:S3 -> S5 -> S6 -> S7
(4) P12:优化关键路径
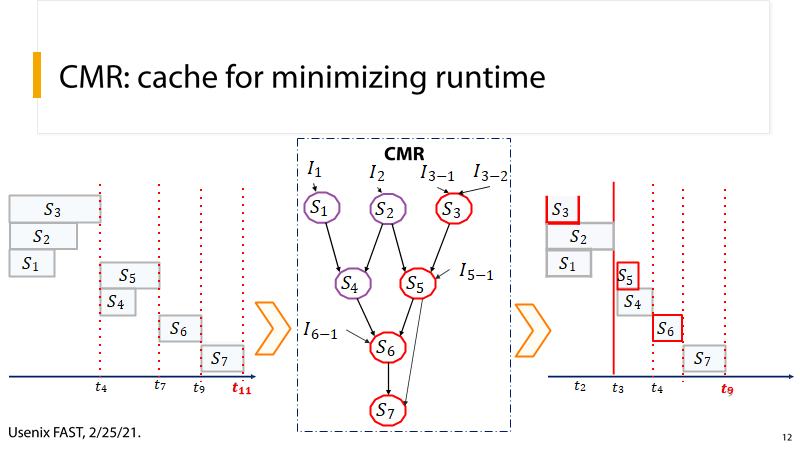
P12:CMR首先对关键路径上的执行单元进行优化,例如提升数据预取、数据缓存等操作的优先级,可以缩短这一关键路径
(5) P13:多次优化关键路径
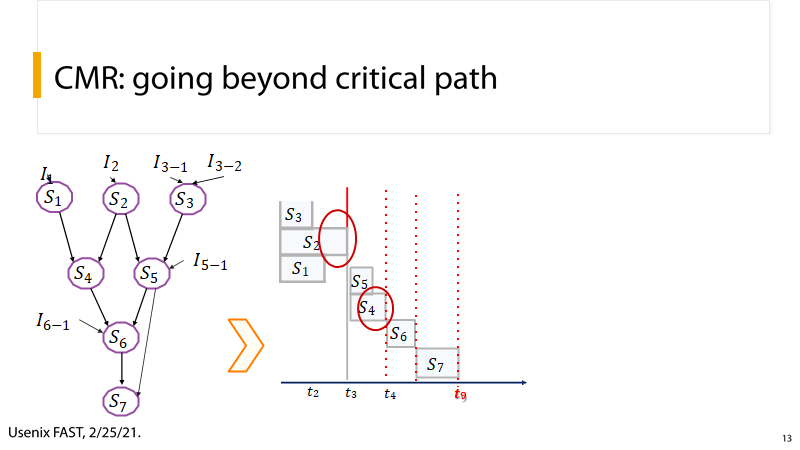
P13:优化完毕后,会产生新的关键路径,于CP不同,CMR会通过多次优化,使系统达到最优性能。
CP利用stage运行时预测来缓存数据,以减少DAGs中stage的关键路径。CMR依赖于Kariz对部分文件缓存的支持,从DAG的每个阶段预取部分数据,以提高单个关键路径之外的性能。
(6) P14:优化前后时空图对比
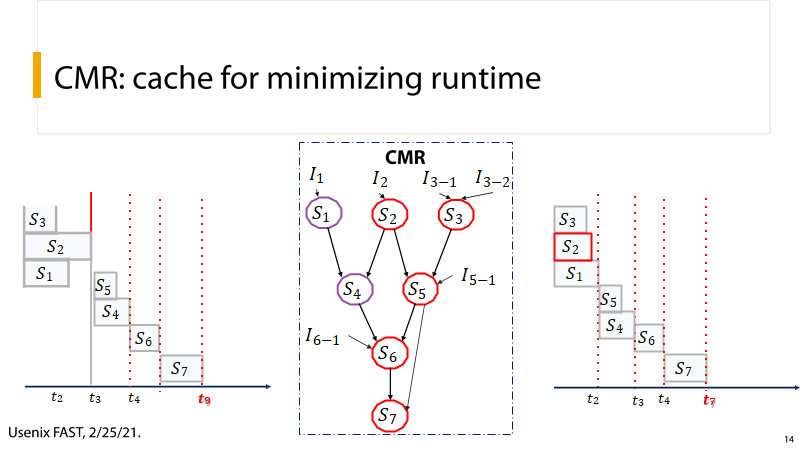
P14:这张图描述了优化前和优化后的数据流图。
5. 方案实现
(1) P15:优化思路

P15:对DAG的预取和缓存进行优先级排序,使它们之间的数据共享最大化,以最小化后端存储负载并最大限度地减少运行时
(2) P16:总体架构
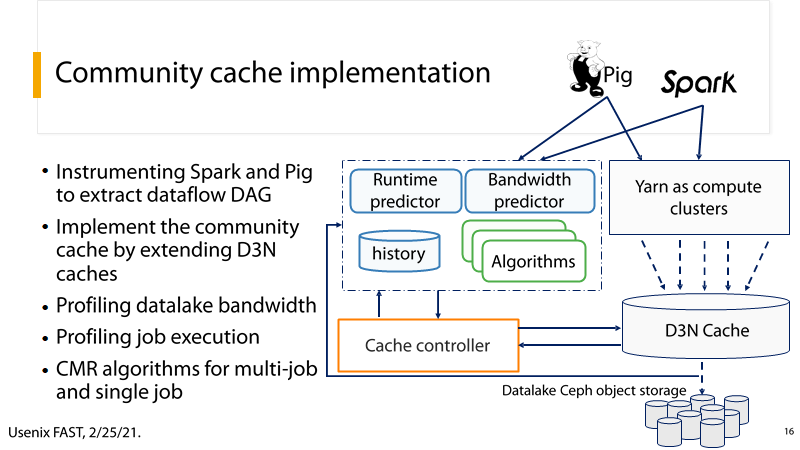
P16:
- 使用分析框架获取DAG
- 通过拓展D3N实现community cache
- 分析datalake带宽
- 分析任务执行情况
- CMR算法:多次优化关键路径
6. 测试
(1) P17:
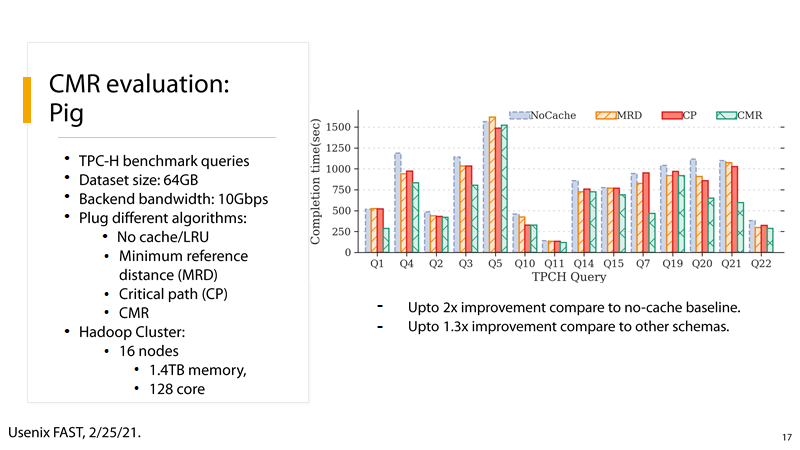
P17:在Pig大数据分析框架下,使用 TPC-H benchmark进行测试,数据的规模是64GB,集群规模是16个节点,1.4TB内存和128个cpu核心,由测试结果可知,采用CMR算法相较于无cache的情形性能提升了2倍,相较于其他cache算法性能提升了1.3倍
(2) P18:
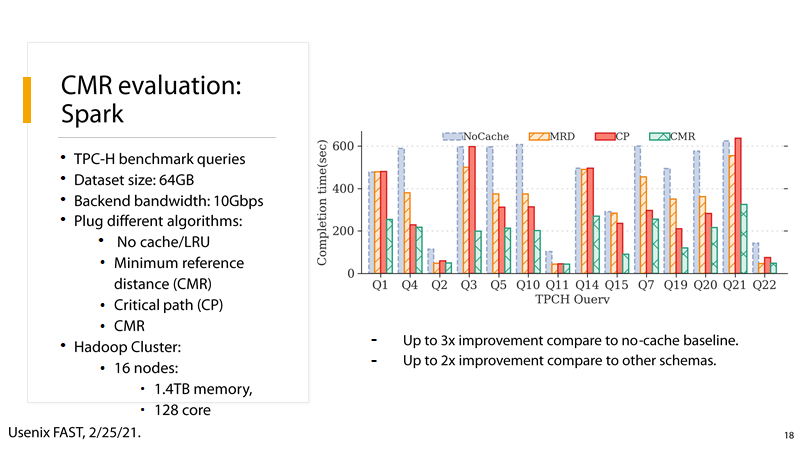
P18:在Spark大数据分析框架下,使用 TPC-H benchmark进行测试,数据的规模是64GB,集群规模是16个节点,1.4TB内存和128个cpu核心,由测试结果可知,采用CMR算法相较于无cache的情形性能提升了3倍,相较于其他cache算法性能提升了2倍
(3) P19:
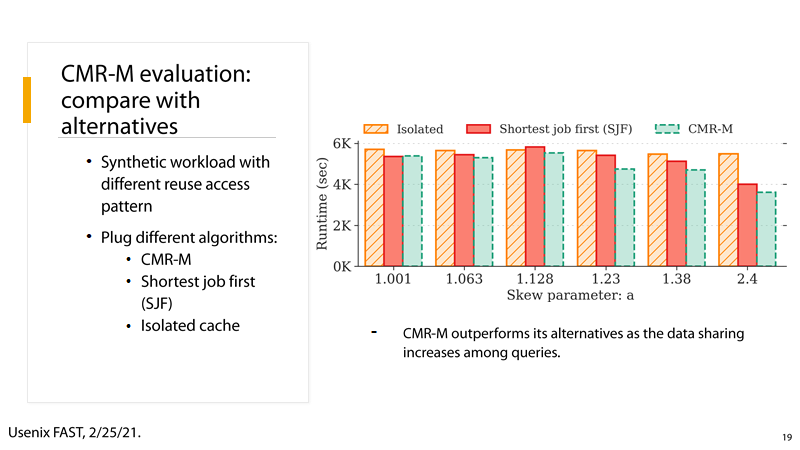
CMR-M:CacheforMinimizing Runtime of multiple DAGs,在选择要缓存和预取的数据时,还考虑了存储带宽和跨多个查询的数据共享。当同一个分析框架存在多个 DAGs 时, CMR-M相较于其他算法能表现出更优地性能,尤其是当数据共享的比例越高,性能优势越明显。
(4) P20:
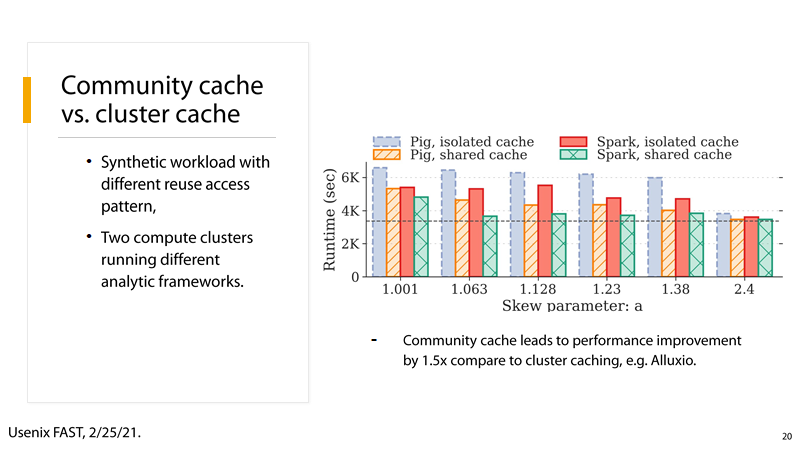
和以Alluxio代表的cluster cache相比,community cache达到更有的性能,接近1.5倍。
7. 结论

通过以上论述,我们可以得出以下结论:
- community cache允许数据在运行不同分析框架的计算集群中共享
- community cache可以获取更加全面的信息,从而更好地进行缓存