1 Java特性
1.1 Java的特点?
- 面向对象(封装、继承、多态)
- 由于jvm的存在,Java和平台无关,一次编译,多地运行
- 编译和解释并存:Java源码→(javac编译)→.class字节码→(JVM解释)→机器码
- 为了加速解释过程,引入运行时编译,即JIT,当 JIT 编译器完成第一次编译后,会将字节码对应的机器码保存下来,下次可以直接使用。
- 支持网络编程和多线程,能很方便地编写出多线程程序和网络程序。
- 自动内存管理,无需像C++一样要手动管理内存。
1.2 JVM、JDK、JRE的区别和联系?
- JVM,Java Virtual Machine:运行Java字节码的虚拟机,在不同平台上有不同的实现(win、linux、macos),是Java语言跨平台的基础。
- JRE,Java Runtime Environment:Java运行时环境,是运行已编译Java程序所需要内容的集合,包括Java虚拟机(JVM),Java类库,java命令和其他一些基础组件,但是它不能创建新程序。
- JDK,Java Development Kit:它是JRE的超集,还包括编译器javac、工具如javadoc、jdb等,能够创建、编译和调试Java程序。
1.3 Java和C++的区别和联系
- Java是面向对象的语言,C++既可以面向对象,也可以面向过程。
- Java不能操作指针,更加安全,C++可以操作指针,更加灵活。
- Java有自动内存管理机制,无需程序员手动释放内存,而C++需要。
- Java的类只支持单继承,C++类支持多继承,Java接口可以多继承。
- C/C++的字符串以’\0’表示结束,但Java中没有这一概念。原因:Java中一切都是对象,字符串对象本身会记录自己的长度,无需浪费额外的空间存储’\0’。
1.4 面向过程和面向对象?
面向过程:分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。
优点:性能比面向对象高,因为类调用时需要实例化,开销比较大,比较消耗资源;比如单片机、嵌入式开发、 Linux/Unix等一般采用面向过程开发,性能是最重要的因素。
缺点:没有面向对象易维护、易复用、易扩展。
面向对象:把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
优点:易维护、易复用、易扩展,由于面向对象有封装、继承、多态性的特性,可以设计出低耦合的系统,使系统 更加灵活、更加易于维护。
缺点:性能比面向过程低。
1.5 为什么说Java编译和解释并存?
Java编写的程序首先需要进行编译,生成字节码文件*.class,这种文件必须由Java解释器来解释执行,同时为了加快解释速度,引入运行时编译JIT,当 JIT 编译器完成第一次编译后,会将字节码对应的机器码保存下来,下次可以直接使用。

2 Java语法
2.1 字符型常量和字符串常量的区别?
- 形式上:字符常量是单引号引起的一个字符;字符串常量是双引号引起的0个或多个字符。
- 含义上:字符常量相当于一个整型值(ASCII值),可以参与表达式运算;字符串常量代表字符串在内存中存放的位置。
- 占内存大小:字符常量占用2字节;字符串常量占用若干字节。
2.2 continue、break、return的区别是什么?
continue:继续下一次循环。break:跳出循环体,继续执行循环体之后的程序。return:结束方法的执行。
2.3 说一说Java泛型?什么是类型擦除?介绍一下常用的通配符?
Java泛型是 JDK 5 引入的一个新特性,提供了编译时类型安全检测机制。
Java的泛型是伪泛型,类型擦除是指在编译期间,所有的泛型信息会被擦除。
常用通配符:
- ? 表示 不确定的Java类型
- T(Type)表示具体的一个Java类型
- K V(Key Value)分别代表Java键值中的Key Value
- E(Element)代表Element
2.4 == 和 equals 的区别?
- == :如果是基本数据类型,==比较的是值是否相同;如果是引用数据类型,==比较的是内存地址是否相等。
- equals():所有对象的父类
Object提供的方法,用于判断两个对象是否相等。分为两种情况:如果子类没有覆盖equals,效果等同于==。如果子类覆盖了equals()方法,通常用来比较两个对象的值是否相同。 - String 中的
equals方法被重写过,判断两个String对象相等的方法:s1.equals(s2) == true或者s1.compareTo(s2) == 0
2.5 hashCode()与equals()
- 说一说
hashCode()?
hashCode() 定义在Object类中,Java1中的任何类都含有hashCode()方法。它的作用是获取哈希码,即一个int整数,用于确定该对象在哈希表中的索引位置。
- 为什么要有
hashCode?
加快对象比较的速度,在插入Map时有很大的作用。如果两个对象的hashCode不同,则这两个对象一定不等,如果hashCode相等,可以再比较对象的值,大大减少了 equals 的次数,相应就大大提高了执行速度。
- 为什么重写
equals时必须要重写hashCode?
equals方法内部会调用 hashcode 只是用来缩小查找成本,而hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等。
- 为什么两个对象拥有相同的
hashcode它们也不一定想等?
因为 hashCode() 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode。
我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。
2.6 自动装箱和自动拆箱
- 装箱:将基本类型用它们对应的引用类型包装起来;
- 拆箱:将包装类型转换为基本数据类型;
2.7 常量池
Java基本类型的包装类大部分(Byte、Short、Integer、Long、Character、Boolean)都实现了常量池,前面4种包装类创建了数值[-128,127]的缓存数据,Character创建了[0,127]范围内的缓存数据,Boolean直接返回True or False,如果超出范围仍然会创建新的对象。
1 | public static void main(String[] args) { |
2.8 重载和重写的区别?
- 重载:同样的一个方法能够根据输入数据的不同,做出不同的处理。
- 重写:当子类继承自父类的相同方法,输入数据一样,但要做出有别于父类的响应时,就要对父类方法进行覆盖,这个过程就叫重写。
以下方法无法被重写:
- 返回值类型、方法名、参数列表必须相同,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。
- 如果父类方法访问修饰符为
private/final/static则子类就不能重写该方法,但是被 static 修饰的方法能够被再次声明。- 构造方法无法被重写
| 区别点 | 重载方法 | 重写方法 |
|---|---|---|
| 发生范围 | 同一个类 | 子类 |
| 参数列表 | 必须修改 | 一定不能修改 |
| 返回类型 | 可修改 | 子类方法返回值类型应比父类方法返回值类型更小或相等 |
| 异常 | 可修改 | 子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等; |
| 访问修饰符 | 可修改 | 一定不能做更严格的限制(可以降低限制) |
| 发生阶段 | 编译期 | 运行期 |
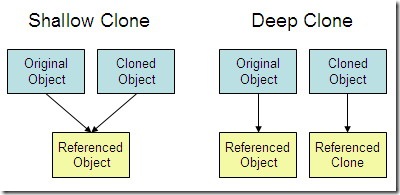
2.9 深拷贝和浅拷贝?
- 浅拷贝:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝
- 深拷贝:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容
2.10 构造器能被重写(override)吗?
构造器不能被重写,但可以被重载。
3 Java面向对象
3.1 面向过程和面向对象的区别?
- 面向过程:函数
- 面向对象:封装、继承、多态
3.2 成员变量和局部变量的区别?
成员变量属于对象,对象存在于堆内存,局部变量则存在于栈内存。特别地,被static修饰的成员变量属于类,位于方法区。
3.3 面向对象的三大特性:封装、继承、多态
- 封装:将对象的一些属性或方法隐藏在内部,不允许外部对象直接访问对象信息,但可以给外部提供一些方法来操作属性。
- 继承:
- 子类拥有父类的所有属性和方法,包括私有的,但私有的只是拥有,无法访问。
- 子类可以拓展父类,拥有自己的属性和方法。
- 子类可以重写父类方法进行覆盖。
- 多态:父类指向子类的实例
- 对象类型和引用类型之间具有继承(类)/实现(接口)的关系;
- 引用类型变量发出的方法调用的到底是哪个类中的方法,必须在程序运行期间才能确定;
- 多态不能调用“只在子类存在但在父类不存在”的方法;
- 如果子类重写了父类的方法,真正执行的是子类覆盖的方法,如果子类没有覆盖父类的方法,执行的是父类的方法。
3.4 对象相等和它们的引用相等
- 对象相等:对象保存在内存中的数据相等
- 引用相等:对象的内存地址相等
3.5 StringBuffer和StringBuilder的区别和联系?
- StringBuffer:线程安全,效率低
- StringBuilder:线程不安全,效率高
3.6 类的构造方法的作用是什么?如果一个类没有声明构造方法,程序可以执行吗?
- 构造方法的作用是完成类对象的初始化工作
- 如果不显式编写构造方法,编译器会自动生成无参构造方法。
3.7 String为什么是不可变的?
String对象用private final char value[]保存字符串,因此不可变(JDK 9 之后采用private final byte value[]保存)
3.8 构造方法的特点
- 和类名相同
- 无返回值
- 可以被重载,不能被重写
4 反射
4.1 谈一谈反射?
- 反射:允许程序在执行期间借助于Refelction API取得任何类的内部信息,并能直接操作任意对象的内部属性及方法
- 正常方式:引入“包类”名称 → 通过new实例化 → 取得实例对象
- 反射方式:实例化对象 → getClass()方法 → 得到完整的“包类”名称
- 优点:让代码更加灵活、为各种框架开箱即用的功能提供了便利
- 缺点:在运行时有了分析操作类的能力,这同样也增加了安全问题。比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点。
4.2 反射的应用场景
Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。这些框架中也用到了动态代理,而动态代理的实现也依赖反射。
- 通过反射创建类对象
1 |
|
- 通过反射访问类属性
1 |
|
- 通过反射调用类方法
1 |
|
- 通过反射访问私有属性、方法、构造器
1 | void test4() throws Exception { |
4.3 注解和反射
基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。(基于注解编程的原理)
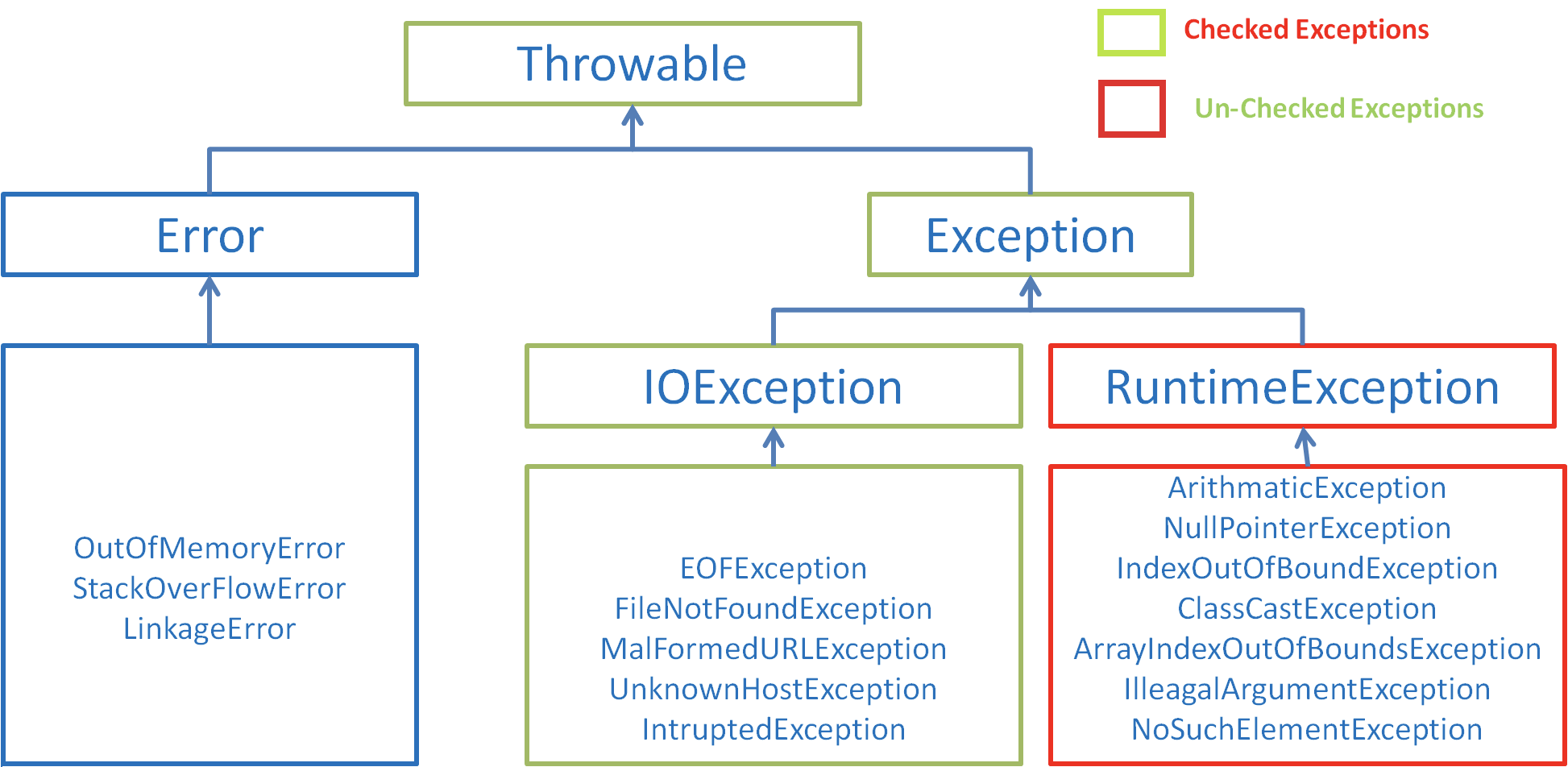
5 异常
6 多线程
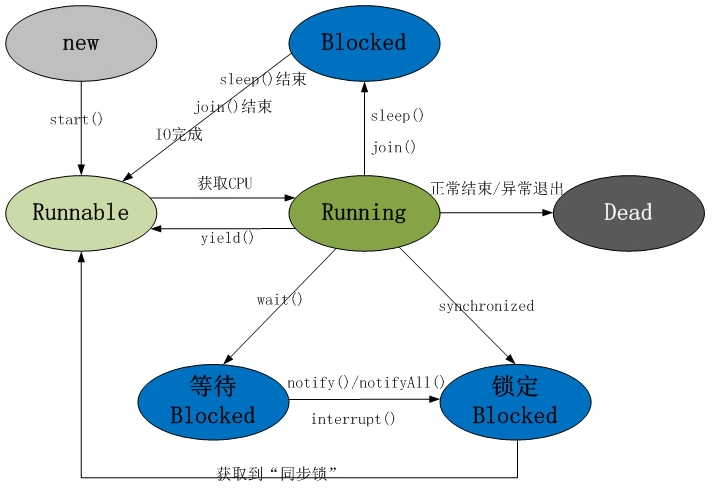
6.1 程序、线程、进程?
- 程序:含有指令和数据的文件,被存储在磁盘或其他的数据存储设备中,也就是说程序是静态的代码。
- 进程:正在运行的一个程序。是资源分配的单位。
- 线程:进程可进一步细化为线程,是一个程序内部的一条执行路径。是调度和执行的单位。
6.2 程序的生命周期
7 I/O流
7.1 I/O流的分类?
- 按数据单位:字节流(8bit)、字符流(16bit)
- 按数据流向:输入流、输出流
- 按流的角色:节点流、处理流
| 抽象基类 | 字节流 | 字符流 |
|---|---|---|
| 输入流 | InputStream | Reader |
| 输出流 | OutputStream | Wrider |
7.2 序列化和反序列化
- 利用序列化和反序列化机制,可以将Java对象持久化,或者在网络中传输。
- 序列化:将数据结构或Java对象转换为二进制字节流。
- 反序列化:将二进制字节流转换为数据结构或Java对象。
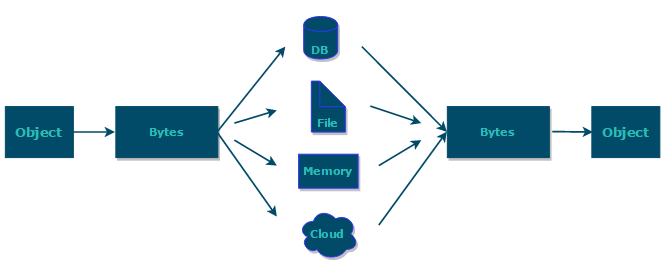
7.3 不想序列化某些属性
transient: 只用于修饰变量,不用于修饰类和方法,被修饰的变量不会被序列化和反序列化。
7.4 获取键盘输入的两种方式
- 使用
Scanner
1 | Scanner input = new Scanner(System.in); |
- 使用
BufferedReader
1 | BufferedReader input = new BufferedReader(new InputStreamReader(System.in); |
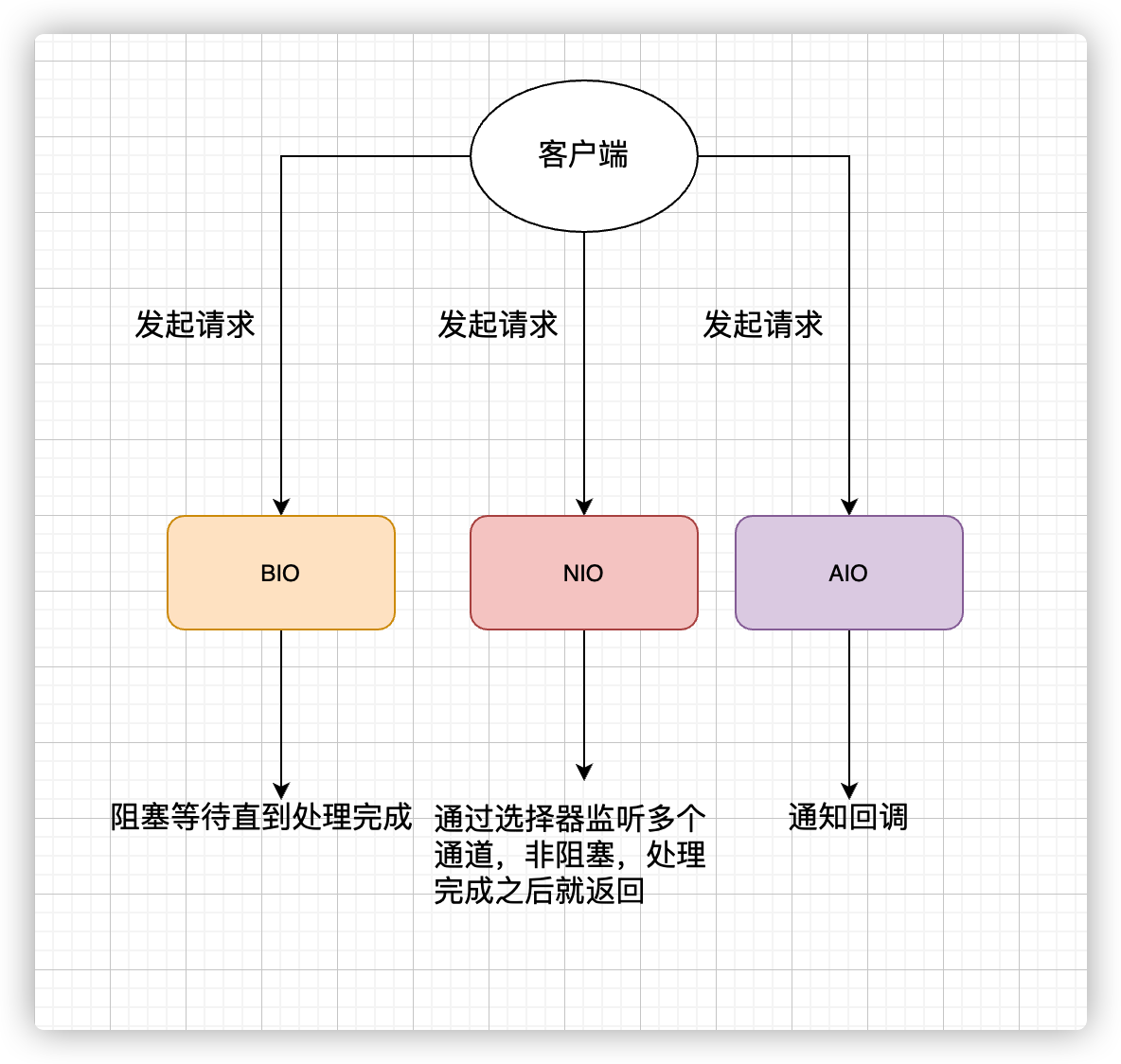
7.5 BIO、NIO、AIO的区别?
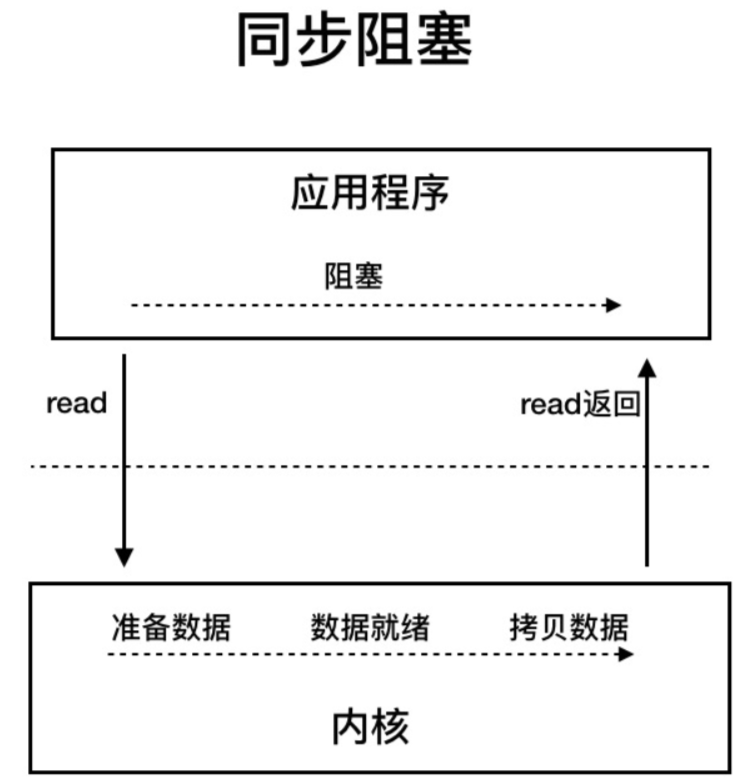
- BIO (Blocking I/O),即同步阻塞I/O,用户发起I/O请求会会一直阻塞,直到内核把数据拷贝到用户空间,不适合高并发场景。
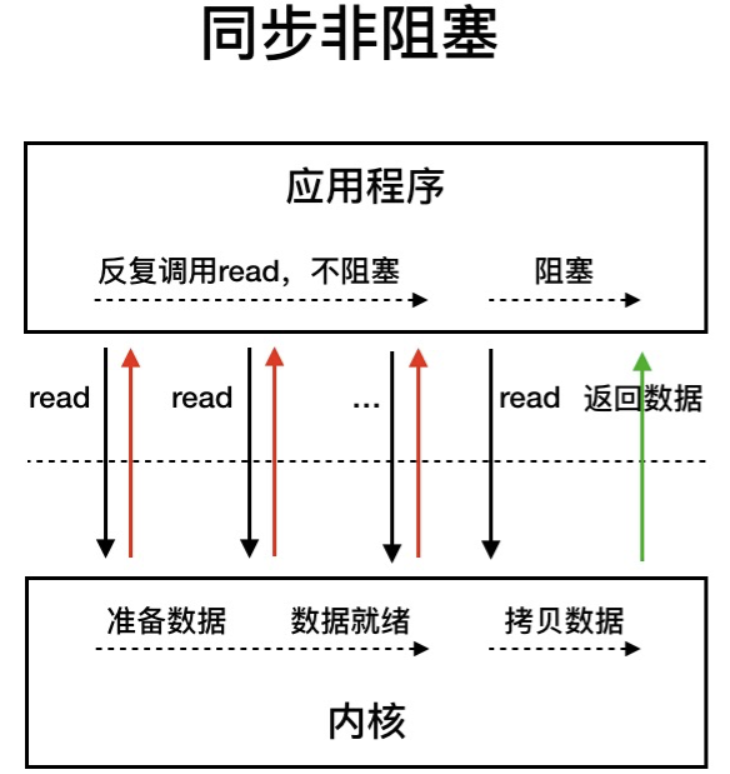
NIO (Non-blocking/New I/O),即同步非阻塞 IO
- 应用程序会一直发起 read 调用,等待数据内核把数据拷贝到用户空间。
- 优点:相比于BIO,同步非阻塞 IO 通过轮询操作,避免了一直阻塞。
- 缺点:轮询过程消耗 CPU 资源。
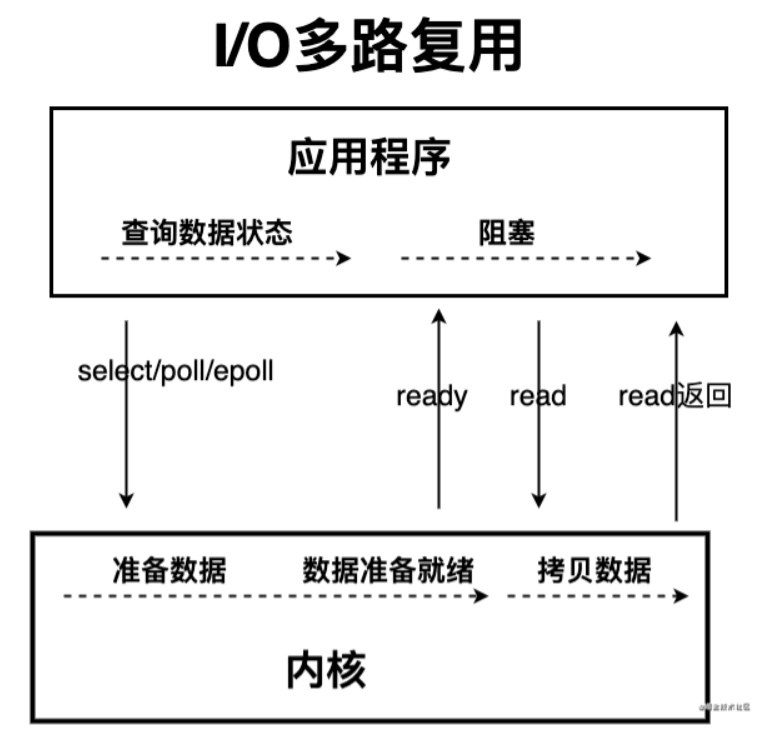
- NIO的I/O 多路复用模型
- 线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。
- 优点:通过减少无效的系统调用,减少了对 CPU 资源的消耗。
- AIO (Asynchronous I/O)
- AIO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
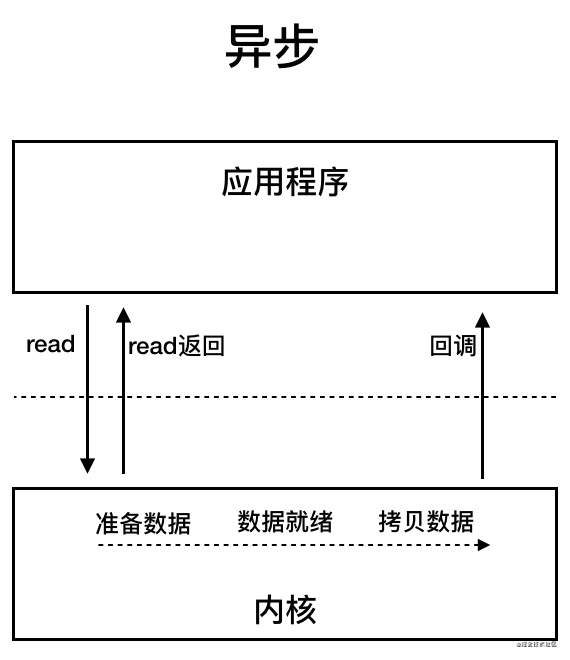
- Summary