
本地事务,是相对于全局事务来说的,适用于单个服务使用单个数据源的场景,简单理解就是单机环境下的事务。
事务的特性
事务的四大特性大家已经耳熟能详了,回顾一下,事务拥有4个特性:ACID
- 原子性(Atomic):同一个事务的多个操作,要么全部成功,要么全部失败。
- 一致性(Consistency):事务前后的数据完整性必须保持一致。
- 隔离性(Isolation):事务之间不能相互影响。
- 持久性(Durability):事务一旦被提交,数据修改都能够正确的被持久化,不会丢失。
多提一句,ACID中的C是最终目的,A、I、D是手段,C的实现需要依靠AID来保证。
在实际开发过程中,本地事务的ACID特性由数据库保证。那么,数据库是如何进行保证的呢?
1. 保证原子性和持久性——日志
1.1 不容忽视的问题——系统崩溃
原子性和持久性是事务最密切相关的两个特性。
原子性保证了事务的多个操作要么全部成功,要么全部失败,不存在中间状态。
持久性保证了事务一旦被提交,修改的数据不会丢失。
我们知道,数据一开始是保存在内存中的,而内存中的数据在系统崩溃后会丢失,只有当数据写入到持久化设备后才能实现持久性。
但是实现原子性和持久性的难点在于数据写入的操作不具备原子性,不仅存在写入和未写入两种状态,还存在正在写的中间状态,所以如果不采取一些措施,将内存中的数据写入持久化设备不能保证原子性和持久性。
具体而言,数据的写入过程可能发生以下情形:
- 未提交事务,写入后崩溃:程序还未修改完所有数据,但部分已修改的数据被写入磁盘,此时出现崩溃,事务执行失败,需要在系统恢复后将已写入的部分数据恢复为事务执行前的状态。
- 已提交事务,写入前崩溃:程序已经修改完数据,但数据还未写入磁盘,此时出现崩溃,由于事务已提交,需要在系统恢复后将数据写入磁盘。
1.2 补救措施——崩溃恢复
为了保证原子性和持久性,需要在系统崩溃后采用补救措施,有两种方式:提交日志,以及影子分页;
提交日志(Commit Logging)
事务提交前,写入提交记录,记录将要执行的操作;
事务提交后,写入结束记录,表示事务已完成持久化。
影子分页(Shadow Paging)
对数据的变动会写入到磁盘中,写入过程是先对原数据进行复制,然后修改复制后的数据。当事务成功提交,修改数据的引用指针,将引用从原数据指向复制后的数据,由于”修改指针的操作“可以认为是原子操作,从硬件上保证了原子性和持久性。
由于影子分页实现并发能力相对优先,因此在高性能数据库中的应用不多。
1.3 提交日志的不足
日志一旦写入Commit Record,那么整个事务就是成功的,即使在修改数据时崩溃了,重启后也可以根据日志进行重新写入,保证了持久性;
日志在写入Commit Record系统崩溃,那么系统重启后会看到一部分没有Commit Record的日志,此时将这部分日志标记为回滚状态即可,保证了原子性。
但是,Commit Logging存在一个致命问题,就是对数据的真实修改都发生在事务提交以后,那么在此之前即使磁盘I/O有足够空闲、即使修改的数据量很大、即使占用了大量缓冲区,也不能修改数据,对提升数据库的性能十分不利。
1.4 改进方案——Write-Ahead Logging
为了解决Commit Logging的不足,IBM研究院发表了《ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging 》,提出“Write-Ahead Logging”日志方案。
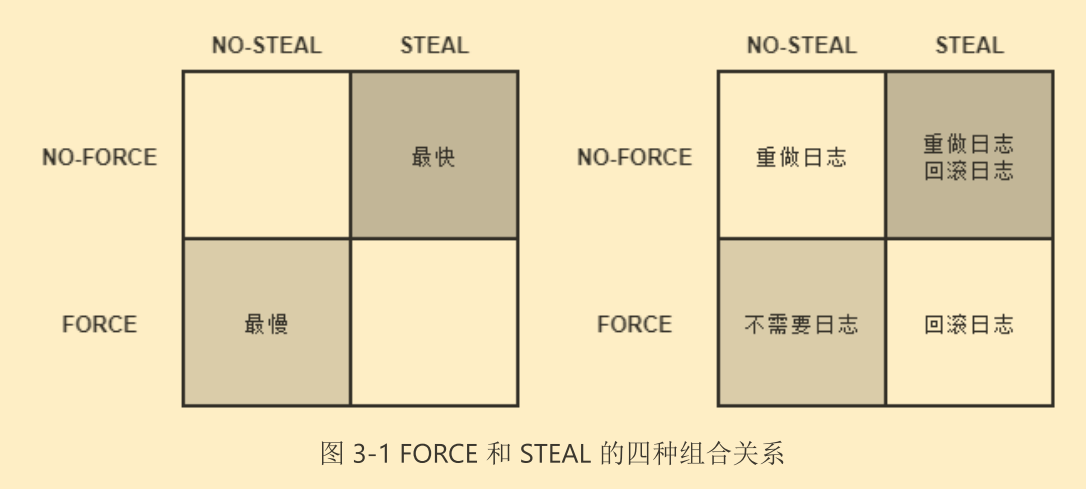
“Write-Ahead Logging”日志方案允许在事务提交之前提前写入变动数据。按照事务提交时点为界,划分为FORCE和STEAL两类情况。
- FORCE:事务提交后,要求变动数据必须同时完成写入成为FORCE,如果不强制变动数据必须同时完成写入则成为NO-FORCE。大多数据库采用NO-FORCE方案,因为只要有了日志,变动数据随时可以持久化,从优化I/O考虑,没必要强制数据写入立即执行。
- STEAL:事务提交前,允许变动数据提前写入成为STEAL,不允许成为NO-STEAL。从优化I/O考虑,允许数据提前写入,有利于利用空闲I/O资源以及节省数据缓冲区内存。
按照这个分类,Commit Logging允许NO-FORCE,不允许STEAL。
Write-Ahead Logging允许NO-FORCE,允许STEAL。
Write-Ahead Logging引入Undo Log,记录了修改了什么位置的什么数据,以便在事务回滚或崩溃恢复时根据Undo Log对提前写入的数据进行擦除。
与Undo Log相对应,此前记录的用于崩溃恢复时重演数据变动的日志被称为Redo Log。
Write-Ahead Logging崩溃恢复的执行流程
- 分析阶段:从最后一次检查点开始扫描日志,找到所有没有End Record的事务,组成待恢复的事务集合。
- 重做阶段:该阶段依据分析阶段中产生的待恢复的事务集合来重演历史(Repeat History),具体操作为:找出所有包含 Commit Record 的日志,将这些日志修改的 数据写入磁盘,写入完成后在日志中增加一条 End Record,然后移除出待恢复事务集 合。
- 回滚阶段:该阶段处理经过分析、重做阶段后剩余的恢复事务集合,此时剩 下的都是需要回滚的事务,它们被称为Loser,根据 Undo Log 中的信息,将已经提前写入磁盘的信息重新改写回去,以达到回滚这些 Loser 事务的目的。
2. 实现隔离性——锁
真实场景下,数据库的访问一定是并发的,自然就会出现同步问题,怎么办?
程序员的都知道,加锁就完事了。
在现代数据库中,均提供了以下三种锁:
- 写锁(Write Lock,又称排他锁,eXclusive Lock,简写为X-Lock):如果数据有加写锁,就只有持有写锁的事务才能对数据进行写入操作,此时其他事务不能写入数据,也不能施加读锁。
- 读锁(Read Lock,又称共享锁,Shared Lock,简写为S-Lock):多个事务可以同时对一个数据添加多个读锁,数据被加上读锁后就不能再被施加写锁。
- 范围锁(Range Lock):对某个范围施加排他锁,这个范围内的数据不能被写入。
2.1 最高隔离级别——可串行化
串行化访问提供了强度最高的隔离性,最直接的方式就是对事务所有读、写的数据全部加上读锁、写锁和范围锁。
但鱼和熊掌不可兼得,隔离程度越高,并发性能越低,现代数据库不考虑性能肯定是不行滴,因此有了次一级的隔离级别——可重复读。
2.2 弱化幻读——可重复读
可重复读对事务所涉及的数据加读锁和写锁,且一直持有至事务结束,不再施加范围锁。
那么,可重复读相对可串行化弱化了哪里呢?
没错,可重复读会出现幻读现象,它是指在事务执行过程中,两个完全相同的范围查询得到了不同的结果集。
1 | /* 时间顺序:1,事务: T1 */ |
假如这条 SQL 语句在同一个事务中重复执行 了两次,且这两次执行之间恰好有另外一个事务在数据库插入了一本小于 100 元的书籍, 这是会被允许的,那这两次相同的查询就会得到不一样的结果,原因是可重复读没有范围锁来禁止在该范围内插入新的数据,这是一个事务受到其他事务影响,隔离性被破坏的表现。
这里的介绍是以 ARIES 理论为讨论目标的,具体的数据库并不一定要完全 遵照着理论去实现。一个例子是MySQL/InnoDB 的默认隔离级别为 可重复读 ,但它在只读事务中可以完全避免幻读问题
2.3 弱化不可重复读——读已提交
可重复读的下一个隔离级别是读已提交(Read Committed),读已提交对事务涉及的数据加的写锁会一直持续到事务结束,但加的读锁在查询操作完成后就马上会释放。读已提交比可重复读弱化的地方在于不可重复读问题(Non-Repeatable Reads),它是指在事务执行过程中,对同一行数据的两次查询得到了不同的结果。譬如笔者想要获取 Fenix’s Bookstore 中《深入理解 Java 虚拟机》这本书的售价,同样执行了两条 SQL 语句,在此两条语句执行之间,恰好另外一个事务修改了这本书的价格,将书的价格从 90 元调整到了 110 元,如下 SQL 所示:
1 | SELECT * FROM books WHERE id = 1; /* 时间顺序:1,事务: T1 */ |
如果隔离级别是读已提交,这两次重复执行的查询结果就会不一样,原因是读已提交的隔离级别缺乏贯穿整个事务周期的读锁,无法禁止读取过的数据发生变化,此时事务 T2 中的更新语句可以马上提交成功,这也是一个事务受到其他事务影响,隔离性被破坏的表现。假如隔离级别是可重复读的话,由于数据已被事务 T1 施加了读锁且读取后不会马上释放,所以事务 T2 无法获取到写锁,更新就会被阻塞,直至事务 T1 被提交或回滚后才能提交。
2.4 弱化脏读——读未提交
读已提交的下一个级别是读未提交(Read Uncommitted),读未提交对事务涉及的数据只加写锁,会一直持续到事务结束,但完全不加读锁。读未提交比读已提交弱化的地方在于脏读问题(Dirty Reads),它是指在事务执行过程中,一个事务读取到了另一个事务未提交的数据。譬如笔者觉得《深入理解 Java 虚拟机》从 90 元涨价到 110 元是损害消费者利益的行为,又执行了一条更新语句把价格改回了 90 元,在提交事务之前,同事说这并不是随便涨价,而是印刷成本上升导致的,按 90 元卖要亏本,于是笔者随即回滚了事务,场景如下 SQL 所示:
1 | SELECT * FROM books WHERE id = 1; /* 时间顺序:1,事务: T1 */ |
不过,在之前修改价格后,事务 T1 已经按 90 元的价格卖出了几本。原因是读未提交在数据上完全不加读锁,这反而令它能读到其他事务加了写锁的数据,即上述事务 T1 中两条查询语句得到的结果并不相同。如果你不能理解这句话中的“反而”二字,请再重读一次写锁的定义:写锁禁止其他事务施加读锁,而不是禁止事务读取数据,如果事务 T1 读取数据并不需要去加读锁的话,就会导致事务 T2 未提交的数据也马上就能被事务 T1 所读到。这同样是一个事务受到其他事务影响,隔离性被破坏的表现。假如隔离级别是读已提交的话,由于事务 T2 持有数据的写锁,所以事务 T1 的第二次查询就无法获得读锁,而读已提交级别是要求先加读锁后读数据的,因此 T1 中的查询就会被阻塞,直至事务 T2 被提交或者回滚后才能得到结果。
2.5 乐观锁和悲观锁
前面介绍的加锁都属于悲观加锁策略,即认为如果不先做加锁再访问数据,就肯定会出现问题。
相对地,乐观加锁策略认为事务之间数据存在竞争是偶然情况,没有竞争才是普遍情况,这样就不应该在一开始就加锁,而是应当在出现竞争时再找补救措施。
没有必要迷信什么乐观锁要比悲观锁更快的说法,这纯粹看竞争的剧烈程度,如果竞争剧烈的话,乐观锁反而更慢。
Reference:
[1] http://icyfenix.cn/architect-perspective/general-architecture/transaction/local.html